The JMdictDB web backend now uses WSGI and the Flask web framework rather than CGI. The installation docs are still being revised but some instructions for upgrading an existing site are available here: http://www.edrdg.org/~smg/doc/2021-11-update.html November 2021 WSGI Upgrade.
The CGI backend remains available but is deprecated and will be removed in the future.
A simpler installation procedure has been implemented that allows the JMdictDB software to be installed and configured for per-user use or system-wide. Once installed, the installed version is completely independent of the Git repository it was installed from allowing the latter to be removed, used for development, etc. without affecting the former. The installation documentation was rewritten and simplified.
In support of this, the directory structure of the source code has been completely reorganized.
A number of internal refactorings have been made in order to make the code more maintainable.
The changes are too numerous to list here in full, please see:JMdictDB is an open source project that provides a Postgresql database, Python API and web CGI front-end for storing and maintaining Japanese / multilingual dictionary data, primarily in support of Jim Breen's Japanese-English dictionary projects including: JMdict, JMnedict, Kanjidic2 WWWJDIC and others. Jim runs these projects under the auspices of the Electronic Dictionary Research and Development Group EDRDG).
The goals of this project (in priority order) are:
Discussion of this project takes place on the Google Groups Edict-JMdict mailing list (edict-jmdict+subscribe@googlegroups.com / https://groups.google.com/g/edict-jmdict/about / https://www.edrdg.org/jmdict_edict_list). Jim Breen maintains a web page describing the JMdict project's use of JMdictDB at http://www.edrdg.org/wiki/index.php/JMdictDB_Project.
The project code is still undergoing active development and no promises are made regarding stability or backward compatibility. However, it is currently in use as the primary repository for the JMdict project dictionary data and the web interface is in use for submitting new entries and corrections to existing entries in WWWJDIC.
All the code developed for this project is GPL'd and maintained in a publicly accessible Git repository (links below). Additional help is welcome; please post to the edict-jmdict mailing list, or email the current principal developer at the address at the bottom of this page.
The code currently consists of scripts to create and load JMdict (and related data such as the JMnedict "Japanese names" file, or the Tatoeba "examples" file) into a Postgresql database, some maintenance and other command line tools, and a set of CGI scripts to allow access and updating of the database using a web browser. The code is written in Python-3 (Python-2 is no longer supported) and is tested under Ubuntu Linux. More information on prerequisites is in the doc/install.html file. file.
Access to the instance of JMdictDB running at Jim Breen's edrdg.org site is through either the Edit links at on words looked up at wwwjdic or directly at: Simple Search, Advanced Search, New Entry, Recent Updates.
jmdictdb
-- JMdictDB project hosted at GitLab.
Issue tracker
-- Issue tracker (at GitLab) for the JMdictDB project.
jmdictdb.tar.gz
-- Download source code, latest development version (gzipped tar file).
install.html
-- The INSTALL file, includes prerequisites and installation instructions.
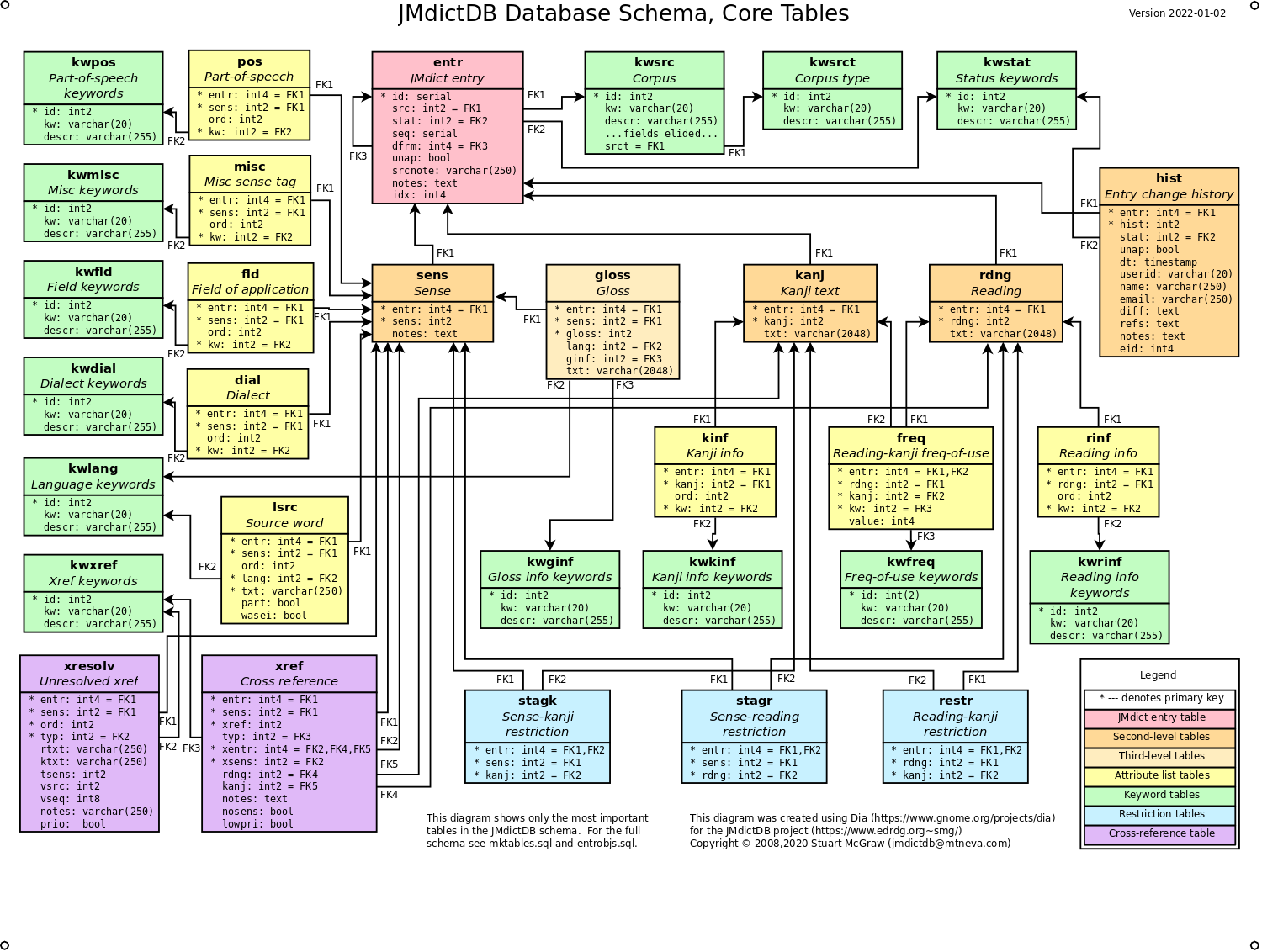
schema.html
-- Comprehensive description of the database schema (2008-11-12).
schema.png, schema.pdf
-- Diagram of the database schema (200KB, 2008-11-12).
The following links provide details about the implementation and use of JMdictDB at Jim Breen's EDRDG (Electronic Dictionary Research and Development Group) website (http://edrdg.org), for receiving new entry and correction suggestions for wwwjdict:
{kind=link}